Why are Denial of Service attacks still dangerous for modern enterprises?
Denial of Service attacks remain a serious enterprise threat because they go beyond temporary disruption. Threats have evolved rapidly, and are multi-vector, often blending volumetric flooding with application-layer exhaustion across hybrid cloud infrastructure. The real danger lies in how they mask intrusion attempts, lateral movement, and data exfiltration to overwhelm SOC teams and degrade the visibility that detection depends on.
There’s a particular kind of silence that falls over a building when systems go down. Not the silence of a scheduled maintenance window, where everything feels planned and controlled. A different kind where phones start ringing, Slack explodes, and executives are walking into the SOC asking questions.
The first instinct is to assume its infrastructure. A misconfigured load balancer or a routing loop. Something internal. The idea that an external actor is involved takes a few minutes to land.
That delay makes a difference. Every minute your team spends ruling out internal causes is a minute the attack continues, your customers notice, and your revenue bleeds quietly into a support queue.
Denial of Service attacks sometimes masquerade as degraded performance. Sometimes they look like a CDN anomaly. Sometimes they’re buried inside a spike that your monitoring tools flagged as “elevated but within threshold.”
And by the time an external attack is confirmed, the business is already asking how long until we’re back. It is this ambiguity in the early moments that keeps denial of service attacks so disruptive for modern enterprises.
How Modern Denial-of-Service Attacks Outsmart Traditional Defenses?
Most companies believe that they are protected from DDoS because they have a well-intentioned risk assessment, a vendor relationship, or a line item in a contract with a cloud provider. And on paper, it is correct.
But Denial-of-Service attacks have evolved from the volume game that shaped the industry’s early mitigation playbooks.
Modern distributed denial-of-service attacks are not about sending huge amounts of traffic. Attackers use smarter methods. For example, they slowly overload login pages, user sessions, and APIs so the attack looks like normal activity. At the same time, they may launch sudden traffic bursts using different techniques such as UDP and web request floods. By constantly changing their approach, they make it difficult for security teams to investigate quickly. In many cases, these attacks are carefully designed to stay just below the limits that would normally trigger automatic protection systems.
The threat has also expanded geographically and technically. Botnets today aren’t just compromised home routers. They’re cloud instances, misconfigured IoT infrastructure, containerized environments, and resources that can generate enormous request volumes from hundreds of autonomous nodes that share no observable pattern.
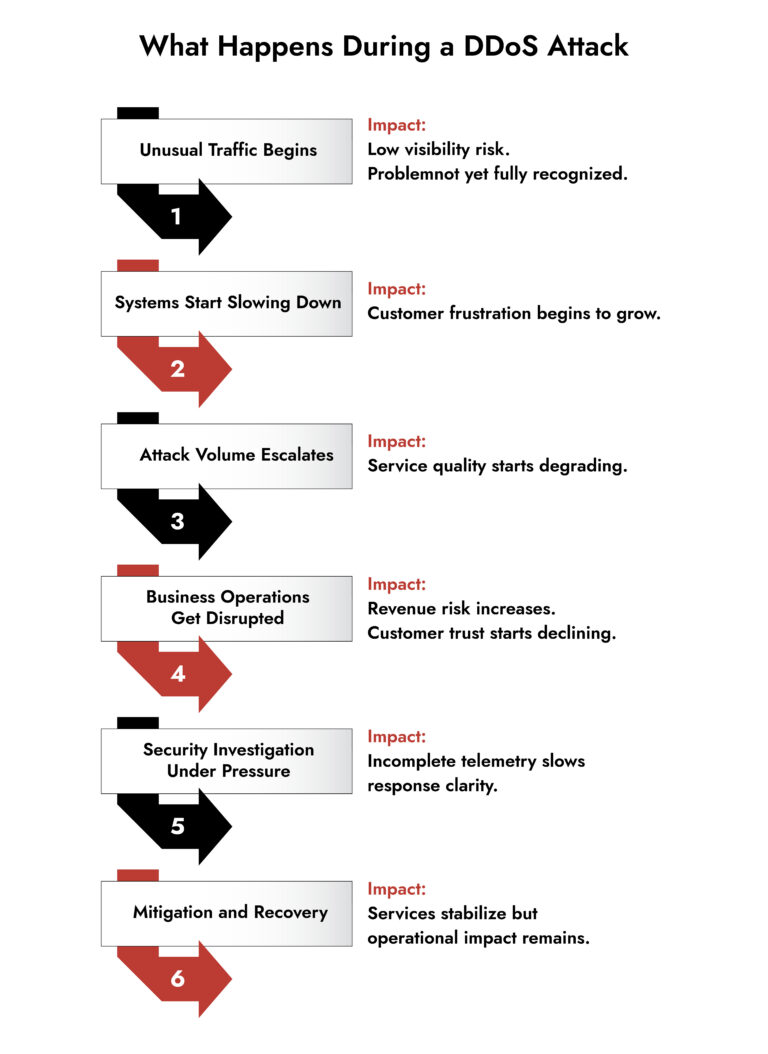
Why Shared Responsibility Gaps Keep DDoS Risk Alive
During many post-incident reviews, it is noticed that often no team is actively addressing the issue because each assumed someone else was handling it! For example, the upstream provider believed the customer’s WAF was filtering the traffic. The SOC assumed the DDoS scrubbing service had already engaged. Meanwhile, the network team was waiting for confirmation from the SOC before making routing changes. No one was taking the action that actually mattered.
This coordination failure is actually a clarity failure. In the absence of real-time telemetry that clearly shows what’s happening, where the attack is landing, and what’s passing through your defenses, teams default to assumptions. Situations like this are why denial of service incidents continue to catch otherwise mature organizations off guard.
The challenge is compounded by how enterprises have evolved. With hybrid cloud deployments, multi-CDN strategies, and containerized workloads spread across availability zones, the attack surface doesn’t consolidate neatly anymore.

Denial of service attacks persist as a serious business risk because they disrupt more than infrastructure. They strain visibility, slow decision-making, and can mask deeper intrusion attempts. Enterprises that focus only on mitigation often miss the bigger challenge: maintaining investigative clarity and operational confidence during high-pressure availability incidents.
— Ibrahim Badawi, Sales Engineer, NetWitness
Why DDoS Incidents Still Overwhelm Security Teams in Real Time
When a traffic flooding campaign hits a production environment at scale, the first twenty minutes feel less like a security incident and more like a performance debugging session. Alerts often point to downstream symptoms, such as slow query warnings, timeout thresholds, and health checks failing. Analysts try to stitch together a picture from tools that weren’t designed to talk to each other under load.
In practice, this erosion of clarity is often more damaging than the initial traffic surge itself.
After some time, an attack is confirmed. And now the SOC is managing two things simultaneously: the attack itself, and the organizational response to the attack. Engineers want network diagrams. Legal wants to know about data exposure. Communications wants a customer-facing statement. Executives want ETAs.
Meanwhile, the analysts who actually need to work the problem are fielding questions.
This is where cybersecurity risk management theory and operational reality diverge dramatically. In theory, you have runbooks, escalation paths, clean separation between the response team and the communications function. In practice, during a sustained availability event, SOC pressure is real, distraction is real, and the cognitive load of managing an attack while simultaneously briefing stakeholders is significant.
And here’s the piece that rarely makes it into incident reports: during sustained high-volume attacks, visibility degrades. Log ingestion pipelines get stressed. Packet captures get dropped. Tools that rely on complete data streams start producing partial telemetry. The very moment when you need the clearest picture of your environment is often the moment your instrumentation is working hardest to keep up.
Why the Real Cost of DDoS Is Bigger Than Downtime
Quantifying the business impact of a denial-of-service attack is harder than it looks on a spreadsheet. Direct revenue loss is the obvious figure, and it’s usually the one that appears in post-incident reviews. But it’s rarely the most significant one. What doesn’t get captured cleanly:
The reputational signal sent to customers who encountered errors during a high-stakes moment and quietly didn’t come back. The security team’s credibility is damaged when leadership realizes the organization’s response was reactive and fragmented rather than confident and coordinated.
The partner trust implications when an API gateway your enterprise provides to downstream clients goes dark for two hours, and nobody proactively communicated what was happening or why.
The internal morale cost of a team that spent a brutal shift firefighting, then faced a post-incident process focused on blame rather than systemic improvement. Denial of Service attacks are increasingly recognized in mature organizations as business continuity events, not purely technical incidents.
Make Smarter Security Investments—Faster
- Standardize vendor evaluation with a comprehensive RFI checklist.
- Compare platforms based on real-world detection, visibility, and response capabilities.
- Reduce risk by identifying gaps before deployment.
- Empower security leaders with actionable insights from NetWitness.

Why Traffic Mitigation Alone Cannot Eliminate DDoS Risk
There’s a version of DDoS defense that is entirely upstream and entirely passive from the enterprise’s perspective. Traffic gets scrubbed by a cloud provider or a specialty mitigation service, clean traffic gets forwarded, and the enterprise never sees the raw attack volume at all.
That’s genuinely valuable. But it creates a visibility blind spot that sophisticated threat actors have learned to exploit.
If your entire detection capability during a high-traffic event is focused on network volume, you’re not watching the east-west traffic inside your environment. You’re not correlating authentication anomalies against the flood event. You’re not noticing the service account that started querying the identity provider seventeen times in four minutes.
This is the conversation that needs to happen more frequently between network security teams and the broader SOC: DDoS mitigation and threat detection are not the same problem. Mitigation handles availability. Detection handles everything the attack is designed to conceal.
Building defense capability that addresses both simultaneously is harder, but it’s the standard that modern threat campaigns demand.
Why Lack of Visibility Keeps DDoS a Business Threat
The organizations that handle these events best share a specific characteristic: they don’t wait for the attack to end before they start understanding it. That requires deep network telemetry, not just volumetric metrics, but packet-level visibility that can surface protocol abuse, session manipulation, and behavioral anomalies within the attack traffic itself. It requires the ability to correlate what’s happening at the perimeter with what’s happening inside the environment in near-real time, even as log volumes spike.
It also requires prior investment in context. Knowing what your baseline traffic patterns look like, which services communicate with which endpoints, and which users access which resources is what makes detection meaningful during an availability disruption. Without it, you’re looking at a noisy dashboard during a high-stress event and trying to make judgment calls with incomplete information.
Some organizations are operationalizing this through platforms that bring network detection and response capabilities together with log correlation and identity analytics. The goal is to surface the right signal faster, particularly when the environment is under stress and visibility is most likely to degrade.
Tools like NetWitness, for example, are increasingly used by enterprise SOCs precisely because they’re designed for environments where the attack surface is complex, and the need for investigative clarity during high-volume events is non-negotiable. Not as a replacement for mitigation infrastructure, but as the investigative layer that sits behind it.
How NetWitness Helps Security Teams See Through a DDoS Event
During an active attack, full-packet capture keeps running even when log pipelines are stressed, so your SOC has real telemetry to work with, not sampled flow data and guesswork. Behavioral analytics surfaces the anomalies that matter: the service account that started acting differently mid-flood, the internal endpoint making connections it’s never made before. These are the signals that tell you whether this is a pure availability attack or a smokescreen for something worse.
NetWitness also correlates network telemetry with endpoint, identity, and cloud data in a single incident timeline which is exactly what you need when your analysts are fielding leadership questions and trying to work the problem at the same time. And because it covers on-premises, virtual, and cloud environments consistently, there are no visibility gaps when the attack traffic starts moving laterally.
The teams that close these incidents cleanly aren’t the ones who had better mitigation. They’re the ones who never lost the picture.
Why Availability Resilience Is Now a Core Security Maturity Indicator
Somewhere along the way, the security industry drew a soft line between availability problems and security problems. Network operations handled uptime. Security operations handled threats. The two disciplines had overlapping tooling and occasionally coordinated, but fundamentally, a DDoS event was treated as a network issue with security implications, not the other way around.
When availability is weaponized by adversaries as a distraction, a coercion mechanism, or a preliminary stage of a multi-phase intrusion campaign, it becomes a core security domain. When your detection capability degrades under high-volume conditions, your overall security posture degrades with it. When your organization’s ability to recover from an availability event is measured in hours rather than minutes, that’s a business risk that lives on the CISO’s register, not just the NOC’s.
The maturity question isn’t whether you have DDoS protection. Most organizations do. The question is whether your security program can maintain investigative clarity and detection fidelity while that protection is active, and whether your team is practicing for the moments when everything is happening at once.
DoS and DDoS attacks are not going away. They’re expanding in sophistication, in scope, and in the strategic role they play in multi-stage campaigns. Organizations that treat availability as a security discipline, and invest accordingly in the detection infrastructure to support it, are building something more valuable than uptime metrics. They’re building the kind of operational confidence that means the next time the business goes quiet, your team already knows what’s happening and what to do about it.
Frequently Asked Questions
1. What is a Denial of Service (DoS) attack?
A Denial-of-Service attack is a deliberate attempt to make a system, network, or service unavailable to its intended users by overwhelming it with traffic or requests, or by exploiting vulnerabilities that cause it to crash.
2. What is the difference between DoS and DDoS attacks?
A DoS attack originates from a single source, and a Distributed Denial of Service (DDoS) attack uses many systems simultaneously, often thousands of compromised devices operating as a botnet. This distributed nature makes DDoS attacks significantly harder to block, because there’s no single IP or source to filter.
3. What are the best cybersecurity tools to protect against a DoS attack?
Effective protection typically combines multiple layers: purpose-built DDoS scrubbing services or CDNs with traffic filtering capabilities, web application firewalls (WAFs), rate-limiting controls at the application and API layer, and network detection and response (NDR) platforms that maintain visibility during high-volume events.
4. How do you detect a DoS attack on a server?
Early indicators include sudden and unexplained spikes in inbound traffic, degraded response times for specific services, connection queue exhaustion, and elevated CPU or memory utilization that doesn’t correlate with expected load. More sophisticated detection involves behavioral baselines.
5. How can I set up a firewall to prevent DoS attacks effectively?
Firewalls play a limited but useful role in DoS defense. Rate-limiting rules, connection-state tracking, and IP reputation filtering can reduce the impact of lower-volume attacks. However, modern distributed denial of service campaigns typically generate traffic volumes that exceed what perimeter firewalls are designed to absorb. For enterprise environments, firewalls should be part of a layered defense strategy that also includes upstream scrubbing services, application-layer controls, and network monitoring.
Unify Security Across Hybrid Environments
- Gain complete visibility across cloud, on-prem, and endpoints.
- Detect threats faster with correlated insights across all layers.
- Reduce complexity with a single, integrated security platform.
- Strengthen your defenses with NetWitness unified security





