
Why and how automated alerts are evolving:
1. The Shift to “Agentic” and Autonomous SOCs
Experts argue that the “Human-in-the-loop” model is failing at scale.
- The Prediction: The “Agentic SOC” will become the standard. This involves AI agents that don’t just alert a human, but independently perform Tier-1 triage – investigating the alert, gathering logs, and even “suppressing” known-safe anomalies before an analyst ever sees them.
- The Impact: Systems are now expected to reduce false positives by 90% or more, shifting the human role from “responder” to “governor” of the automated logic.
2. From Static Thresholds to Behavioral Baselines
Traditional alerts based on fixed limits (e.g., “Alert if CPU > 90%”) are considered obsolete.
- Explainable Anomaly Detection: Prioritize AI that learns the “rhythm” of a specific network. An alert should only fire if a behavior is truly anomalous for that specific hour, user, and asset.
- Dynamic Thresholding: This reduces “noise” caused by routine maintenance or peak business hours, ensuring that when an alert triggers, it is statistically significant.
3. Contextual Intelligence: The “Narrative” Alert
An alert that requires an analyst to “look up” more info is seen as a failure of design.
- The “Whole Story” Requirement: Alerts should arrive with a pre-packaged narrative:
- Identity Context: Who is the user, and is this their usual behavior?
- Asset Criticality: Is this a sandbox server or the payroll database?
- Threat Mapping: Which MITRE ATT&CK technique does this represent?
Expert Consensus: An alert is only as valuable as the context attached to it. Raw telemetry is just “noise”; enriched telemetry is “intelligence.”
4. Convergence of IT and OT (Cyber-Physical Monitoring)
As networks expand into IoT and industrial control systems (OT), watch out for “visibility silos.”
- Unified Visibility: Modern management must consolidate signals from cloud, on-prem, and edge devices into a single pane.
- Standardized Triggers: Using different alerting logic for the “office” vs. the “factory floor” creates security gaps. Look for a unified response framework that treats every endpoint as a potential entry point.
5. Compliance as a “Continuous” State
Manual audits are being replaced by automated, real-time compliance alerting.
- Always-on Auditing: Organizations are moving toward systems that alert immediately when a configuration drifts from regulatory standards (like GDPR or NIS2).
- Governance: This allows companies to prove to regulators that they are in compliance at any given second, rather than just during an annual checkup.

Defining What an Alert Should Represent
Before configuring any network management tools, teams must agree on what qualifies as an alert. This decision shapes alert volume, analyst trust, and response effectiveness.
Alerts should represent conditions that require human judgment or action. They should not mirror every anomaly or metric deviation.
Alerts tend to add value when they reflect:
- Measurable impact on critical assets
- Behavior inconsistent with established baselines
- Known threat patterns supported by context
- Clear investigative or containment paths
Examples that usually warrant alerts include unusual outbound connections from sensitive systems, persistent beaconing behavior, or suspicious lateral movement patterns. Routine congestion, expected configuration changes, or transient packet loss rarely justify escalation.
This discipline anchors the entire network management solution.

How to Set Up Automated Network Alerts and Notifications
Setting up automated alerts requires structure, not guesswork. Successful implementations follow a deliberate sequence.
Establish Complete Network Visibility
Alert quality never exceeds visibility. Effective network management depends on observing traffic across:
- North–south ingress and egress points
- East–west traffic within data centers and cloud environments
- Encrypted traffic metadata
- Session-level interactions rather than isolated packets
NIST SP 800-94 emphasizes that detection accuracy correlates directly with the depth and continuity of network visibility.
Baseline Normal Network Behavior
Alerts should surface deviation, not volume. Establishing baselines allows teams to distinguish legitimate change from suspicious activity.
Baselines often include:
- Typical session durations and sizes
- Common communication paths
- Normal service behavior by time of day
- Expected protocol usage patterns
Modern network monitoring tools apply statistical baselining to reduce false positives without masking genuine threats.
Design Alert Logic That Reflects Risk
Static thresholds break as environments evolve. Alert logic should combine multiple signals.
Effective logic often incorporates:
- Behavioral anomalies
- Protocol misuse
- Asset criticality
- Threat intelligence enrichment
This approach strengthens threat detection and response by tying alerts to security outcomes rather than raw metrics.
Prioritize Alerts by Business and Security Impact
Alert prioritization separates functional network management programs from reactive ones.
Risk scoring models typically consider:
- Asset value
- Threat confidence
- Scope of exposure
- Potential operational impact
Gartner’s 2024 research on SOC maturity highlights risk-based prioritization as a defining characteristic of high-performing security teams.
Deliver Alerts Where Decisions Happen
Alerts lose value when they land in the wrong systems or channels. Routing must reflect operational reality.
Common destinations include:
- SIEM queues for correlation
- SOAR platforms for orchestration
- Secure messaging systems for escalation
- On-call workflows tied to severity
Strong network management solutions treat alert delivery as a design decision, not a default setting.

Reducing Alert Fatigue Without Sacrificing Coverage
Alert fatigue stems from mistrust, not just volume. When alerts consistently lack context or relevance, teams stop responding.
Organizations reduce fatigue by:
- Correlating related alerts before escalation
- Suppressing duplicates tied to the same root cause
- Enforcing minimum confidence thresholds
- Periodically reviewing alert usefulness, not just quantity
These practices reinforce security network management as an ongoing operational process rather than a one-time configuration effort.
Embedding Alerts into a Broader Network Management Strategy
Alerts deliver value only when integrated into larger workflows. Mature network management programs connect alerting to:
- Forensic investigation workflows
- Compliance reporting
- Continuous improvement cycles
This integration distinguishes best network management for security professionals from basic monitoring deployments.
The Role of Network Detection and Response
Alerting becomes significantly more effective when paired with deep investigative capability.
Network Detection and Response platforms emphasize:
- Continuous packet-level visibility
- Session and artifact reconstruction
- Behavioral analytics across encrypted and unencrypted traffic
- Investigation workflows directly tied to alerts
NetWitness NDR follows this model by prioritizing full network visibility and analyst-driven investigation rather than relying solely on abstract indicators. This approach supports stronger network management while preserving analyst autonomy and context. 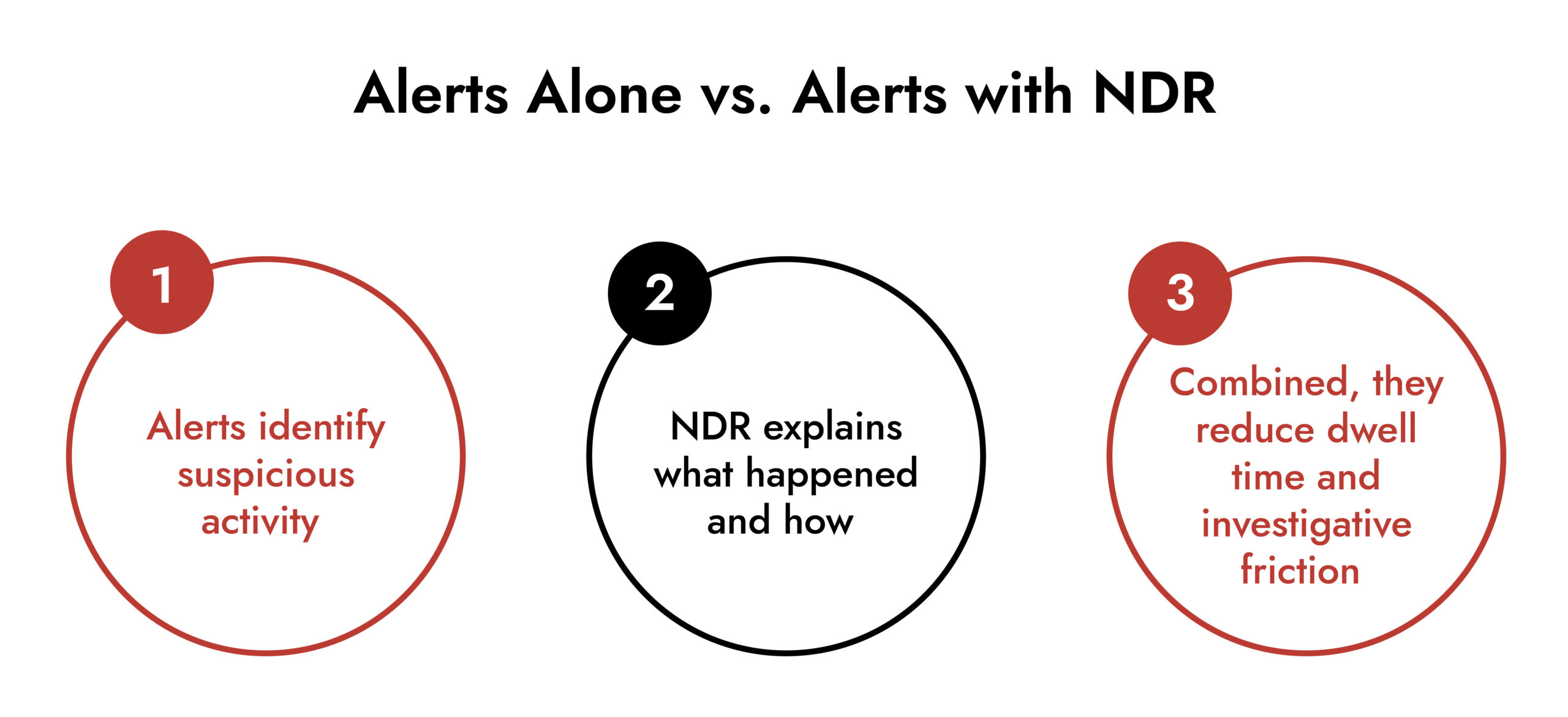
Measuring Whether Your Alerts are Working
Success is not measured by alert volume. It is measured by outcomes.
Organizations track:
- Mean time to detect
- Mean time to respond
- Alert-to-incident conversion rate
- Analyst investigation time per alert
CISA guidance from 2024 highlights detection efficiency as a key predictor of effective incident containment.
Conclusion
Automated alerts reveal how an organization thinks about risk. Poorly designed alerts amplify noise. Well-designed alerts clarify decisions.
Strong network management turns alerts into trusted signals, supports effective threat detection and response, and gives teams the space to investigate instead of reacting. When alerts align with visibility and investigation, they stop competing for attention and start driving outcomes.





